

Even though insurance fraud costs companies billions of dollars each year, detection has historically been a manual process. It relied on human analysts to identify patterns and anomalies in claims data. However, with the advent of big data and advanced analytics techniques, it is now possible to use technology to automate and enhance fraud detection.
Understanding Insurance Fraud
Insurance fraud is the act of intentionally deceiving an insurance company to receive an illegitimate benefit. There are many forms, including:
False claims: This involves submitting a claim for a loss that did not occur or exaggerating the severity of a loss to receive a larger payout.
Staged accidents: This involves deliberately causing an accident to make a false insurance claim.
Premium fraud: This involves providing false information to an insurance company to obtain a lower premium rate.
Identity theft: This involves using someone else's identity to make a false insurance claim.
Underwriting Insurance Fraud
Underwriting insurance fraud occurs when an individual or organization provides false or misleading information to an insurance company to obtain coverage or receive a payout on a claim. This type of fraud can take many forms, including providing false information about the value of insured property, misrepresenting the nature or severity of an injury or loss or failing to disclose relevant information that would affect the insurance company's decision to provide coverage.
Insurance fraud can be costly for insurance companies, as they may end up paying out claims that they would not have approved if they had accurate information. This, in turn, can lead to higher premiums for policyholders as insurance companies seek to recoup their losses.
To prevent underwriting insurance fraud, insurance companies typically conduct thorough investigations of applicants and claims, using a variety of tools and techniques to verify information and detect fraud. These may include background checks, inspections of insured property and analysis of medical records and other documentation.
See also: Disaster Fraud: The Dark Side of Claims
Fraud Detection Process at Underwriting Stage
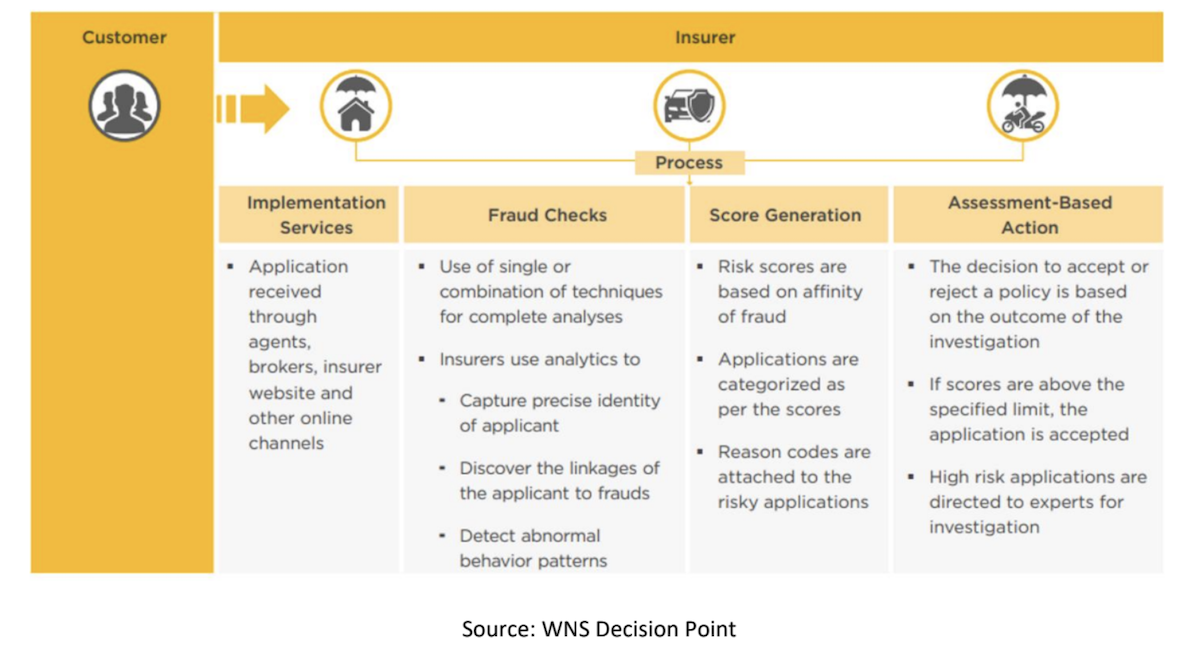
Claims Insurance Fraud
Claims insurance fraud involves deceiving an insurance company to receive an illegitimate benefit. In contrast to underwriting insurance fraud, which involves providing false information during the insurance application process, claims insurance fraud occurs after a policy has been issued and a claim is submitted.
There are different types of claims insurance fraud, including:
Created accidents: This involves deliberately causing an accident to make a false insurance claim.
Exaggerated claims: This involves inflating the amount of damages or injuries suffered to receive a larger payout.
False claims: This involves submitting a claim for a loss that did not occur or that was not covered under the policy.
Multiple claims: This involves submitting multiple claims for the same loss to receive multiple payouts.
Fake billing and submission: This involves submitting a claim for a loss that never occurred, such as claiming a car was stolen when it was not.
These are just a few examples of the many ways in which insurance fraud can occur. Detecting and preventing these fraudulent activities is crucial for insurance companies to maintain profitability and avoid losses.
See also: Coping With Insider and Outsider Fraud
Fraud Detection Process at Claims Stage, Investigation Stage, and Post-Claims Stage
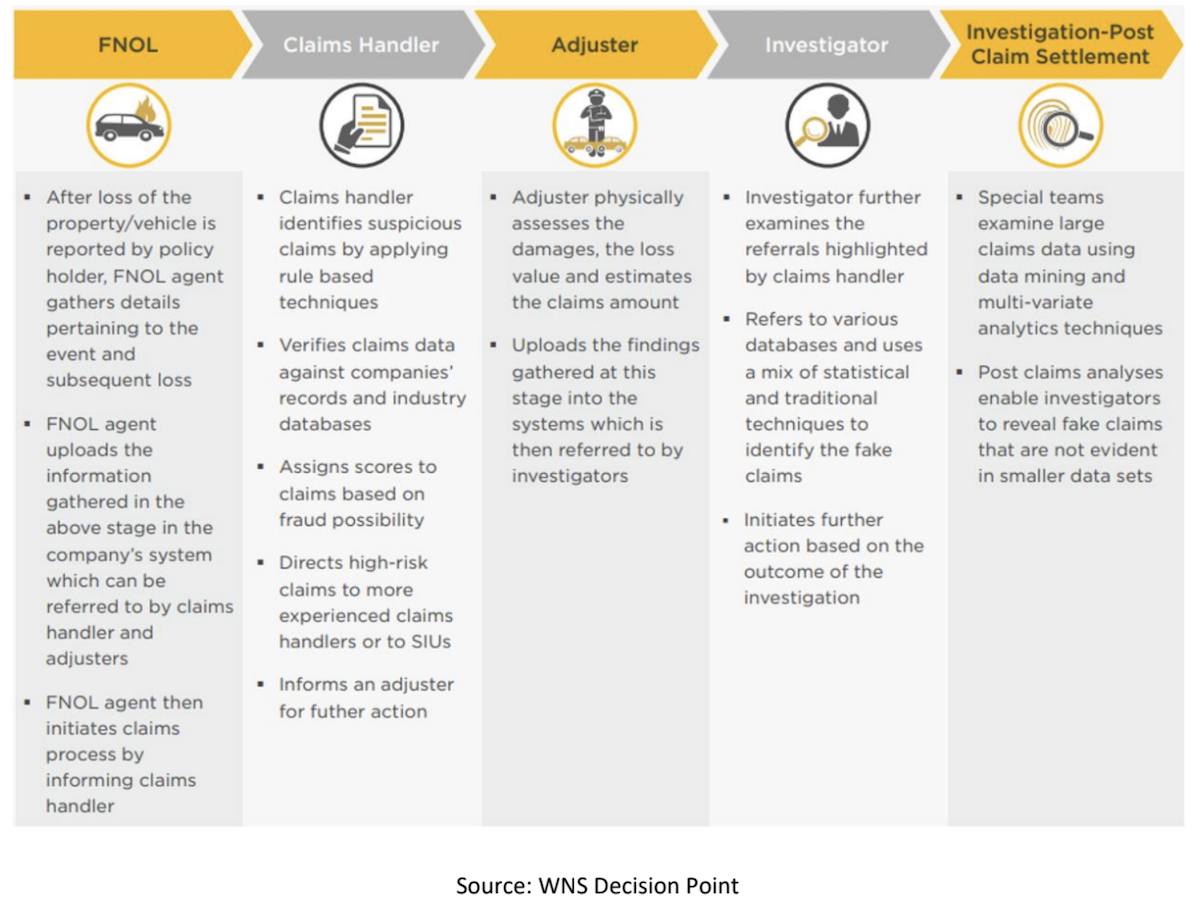
Using Big Data for Fraud Detection
Big data refers to the vast amounts of data that are generated every day from a wide variety of sources. This data includes everything from social media posts and online transactions to medical records and government data. For insurance companies, big data provides a wealth of information that can be used to detect and prevent fraud.
One of the main advantages of big data is that it allows for the creation of detailed profiles of individuals and entities. By collecting and analyzing data from a wide range of sources, insurance companies can gain a comprehensive understanding of a person's behavior and history, making it easier to identify fraudulent activity.
For example, insurance companies can use big data to analyze patterns of behavior, such as how often a person files claims or the types of claims they file. If a person suddenly starts filing a large number of claims or claims for unusual types of losses, this could be a sign of fraudulent activity.
In addition, insurance companies can use big data to detect anomalies in claims data. For example, if a person files a claim for a loss that is far outside the norm for their geographic region or demographic group, this could be a sign of fraudulent activity.
Advanced Analytics Techniques for Fraud Detection
In addition to big data, insurance companies can use advanced analytics techniques. These include:
Machine learning: Machine learning algorithms can be trained to identify patterns in data that are associated with fraudulent activity. By analyzing historical claims data, machine learning models can learn to identify the characteristics of fraudulent claims and flag suspicious claims for further investigation.
Predictive analytics: Predictive analytics models can be used to forecast the likelihood of a claim being fraudulent based on historical data. By analyzing factors such as a person's past behavior and demographic characteristics, these models can assign a fraud risk score to each claim, allowing investigators to focus on the highest-risk claims.
Social network analysis: Social network analysis involves analyzing the connections between individuals and entities to identify patterns of fraudulent activity. By examining the relationships between claimants, insurance companies can identify networks of fraudsters who are working together to commit fraud.
See also: Are You Fraud-Friendly?
The Future of Insurance Fraud Detection
As big data and advanced analytics techniques continue to evolve, the future of insurance fraud detection looks promising. In the years to come, we can expect to see even more sophisticated fraud detection systems that use data and artificial intelligence to identify fraudulent activity in real time.
Adoption Phases of Big Data Analytics
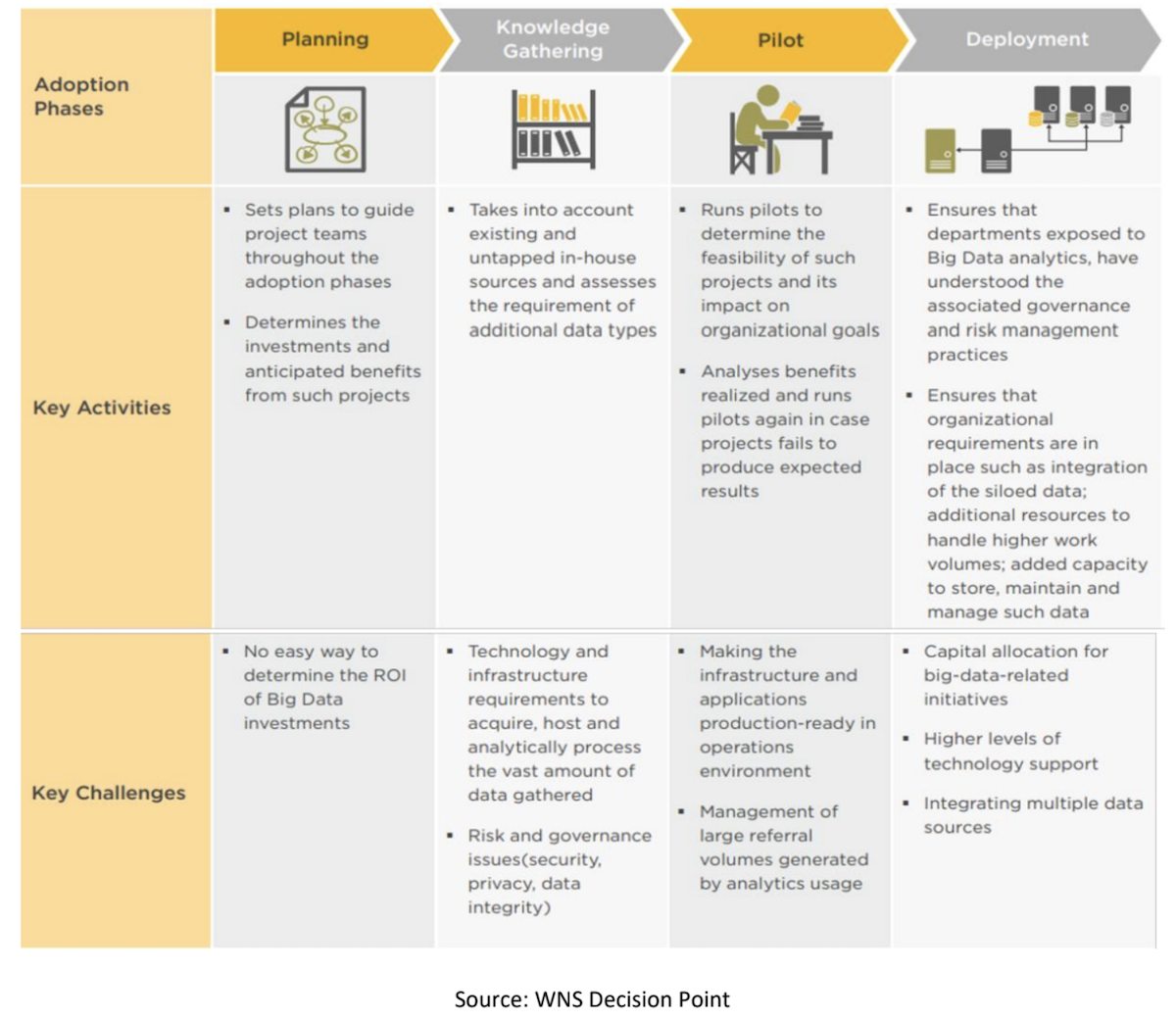
However, fraud detection is not a one-size-fits-all solution. While big data and advanced analytics can provide powerful tools for insurance fraud detection, the industry must be aware of potential challenges and limitations. Here are a few things the industry should look out for:
Data quality: The accuracy and completeness of data are critical for effective fraud detection. If data is incomplete, outdated or inaccurate, it can lead to false positives or false negatives. Therefore, insurance companies should ensure that their data is of high quality and regularly updated.
Privacy concerns: Insurance companies must also be mindful of privacy concerns when collecting and analyzing data. They must comply with data protection regulations and ensure that sensitive personal information is kept secure.
Bias: Machine learning algorithms can be susceptible to bias, particularly if the data used to train them is biased. For example, if historical claims data is biased against certain demographic groups, the machine learning model may perpetuate that bias in its fraud detection. Therefore, it is important to regularly audit and evaluate algorithms for potential bias.
Human intervention: While big data and advanced analytics can automate many aspects of fraud detection, it is still important to have human analysts review and verify suspicious claims. Human expertise is essential for making complex judgments and interpreting the nuances of certain claims.
While big data and advanced analytics can provide powerful tools for insurance fraud detection, it is important for the industry to be aware of potential challenges and limitations. By addressing these challenges and ensuring that data is of high quality, accurate and unbiased, the industry can continue to improve its fraud detection capabilities and prevent losses.



