

The landscape of technology adoption, with artificial intelligence (AI) at the forefront, is rapidly changing industries and economies across the globe. The meteoric rise of ChatGPT to 100 million users in 2023 is a testament to the rapid integration of AI technologies into daily life. This whitepaper analyzes the required evolution of the data strategy in organizations aiming to harness the full potential of AI.
1. Background
The rapid growth and widespread adoption of AI technologies across industries underscore the urgency for organizations to adapt. Grasping the scale of AI's economic influence and its transformative effects on various business functions can help us appreciate the critical role that data plays in driving AI success.
The Economic Impact of AI
Generative AI, a branch of artificial intelligence, is poised to create substantial economic benefits globally, estimated to range between $2.6 trillion and $4.4 trillion annually. This technology is expected to notably affect higher-wage knowledge workers, accelerating productivity growth globally. Approximately 40% of working hours could be influenced by AI, leading to significant job transformations, particularly in advanced economies where around 60% of jobs could be affected. While North America and China are projected to reap the most benefits, Europe and developing countries may experience more moderate increases.
Generative AI's economic impact isn't confined to improving productivity. It extends to reshaping market dynamics, altering competitive landscapes, and allowing the creation of new business models. In sectors like healthcare, generative AI can enhance diagnostic accuracy, personalize treatment plans, and streamline administrative tasks. Similarly, in finance, it can optimize trading strategies, improve risk management, and enhance customer service through intelligent chatbots. The ripple effects of these changes will require successful businesses worldwide to adapt and evolve much faster than their competitors.
Impact Across Business Functions
According to McKinsey, the potential of generative AI will extend across various business functions. In the short term, it is expected that 75% of its value will concentrate in customer operations, marketing and sales, software engineering, and research and development (R&D). Industries such as banking, high-tech, and life sciences are anticipated to witness the most substantial revenue impacts from generative AI.
See also: 'Data as a Product' Strategy
Customer Operations
In customer operations, AI can automate routine inquiries, enhance customer satisfaction through personalized interactions, and provide predictive insights that help anticipate customer needs. Advanced AI systems can analyze customer behavior and preferences, enabling businesses to offer tailored products and services, thus driving customer loyalty and increasing lifetime value.
Marketing and Sales
For marketing and sales, AI-driven analytics can optimize targeting, streamline lead generation processes, and improve conversion rates. AI algorithms can analyze vast amounts of data to identify patterns and trends much faster than human analysts. This capability allows marketers to craft highly personalized campaigns that resonate with individual customers, thereby maximizing the return on marketing investments.
Software Engineering and R&D
In software engineering and R&D, generative AI is accelerating the development process by automating coding tasks, identifying bugs, and suggesting improvements. A prime example of this is GitHub Copilot, an AI-powered code completion tool developed by GitHub and OpenAI. Copilot assists developers by suggesting code snippets, entire functions, and even complex algorithms based on the context of their work. It can significantly speed up coding processes, reduce repetitive tasks, and help developers explore new coding patterns. For instance, a developer working on a sorting algorithm might receive suggestions for efficient implementations like quicksort or mergesort, complete with explanations of their time complexity. AI-driven simulations can also enhance R&D efforts by predicting outcomes of various experiments and guiding researchers toward the most promising avenues. This acceleration not only reduces time-to-market but also fosters innovation and enhances competitive advantage.
2. Challenges Organizations Are Facing With AI
Despite significant investments in data and AI, many organizations grapple with deriving measurable value. Vantage Partners and Harvard Business Review Analytic Services find that 97% of organizations are investing in data initiatives. Ninety-two percent are working with AI/ML in either pilot phases or production. Despite this, 68% fail to realize measurable value from AI. A disconnect exists: While 74% have appointed chief data or analytics officers, 61% lack a data strategy to support machine learning and data science.
The primary reasons for this disconnect include inadequate data quality, lack of skilled personnel, and insufficient integration of AI initiatives with business strategies. Many organizations collect vast amounts of data but struggle with ensuring its accuracy, consistency, and relevance. Additionally, the shortage of AI and data science talent hampers the effective implementation of AI projects. Lastly, without a clear strategy that aligns AI efforts with business objectives, organizations find it challenging to translate AI capabilities into tangible business outcomes.
3. AI Models and Related Learning Processes
Understanding AI models and their learning processes is fundamental to developing an effective data strategy. This knowledge illuminates the specific data requirements for various AI applications and informs how organizations should structure their data pipelines. By first exploring these technical foundations, we establish a clear context for the subsequent discussion on data strategy, ensuring that proposed approaches are well-aligned with the underlying AI technologies they aim to support.
Supervised vs. Unsupervised Learning
In the context of AI, supervised and unsupervised learning represent two primary methodologies of models.
- Supervised Learning
Supervised learning relies on labeled data to train models, where the input-output pairs are explicitly provided. This method is highly effective for tasks where large, accurately labeled datasets are available, such as image classification, speech recognition, and natural language processing. The effectiveness of supervised learning is heavily contingent on the quality and accuracy of the labeled data, which guides the model in learning the correct associations. For enterprises, creating and maintaining such high-quality labeled datasets can be resource-intensive but is crucial for the success of AI initiatives.
The vast majority of enterprise AI use cases fall under supervised learning due to the direct applicability of labeled data to business problems. Tasks such as predictive maintenance, customer sentiment analysis, and sales forecasting all benefit from supervised learning models that leverage historical labeled data to predict future outcomes.
- Unsupervised Learning
Unsupervised learning, on the other hand, involves training models on data without explicit labels. This approach is useful for uncovering hidden patterns and structures within data, such as clustering and anomaly detection. While unsupervised learning can be powerful, it often requires large volumes of data to achieve meaningful results. Enterprises may find it challenging to gather sufficient amounts of unlabeled data, especially in niche or specialized industries where data is not as abundant.
The lack of large datasets within many enterprises to train unsupervised models underscores the importance of data-centric approaches. High-quality, well-labeled datasets not only enhance supervised learning models but also provide a foundation for semi-supervised or transfer learning techniques, which can leverage smaller amounts of labeled data in combination with larger unlabeled datasets.
See also: Data Mesh: What It Is and Why It Matters
The AI Training Loop
AI systems need to be performant and reliable. The AI training loop is a critical process that underpins the development and deployment of such models. Each AI training loop consists of key stages that include data collection and preparation, model training, evaluation and validation, model improvement through tuning and optimization, and monitoring. Each phase is crucial for building robust and reliable AI systems, with a strong emphasis on data quality and iterative improvement to achieve optimal performance.
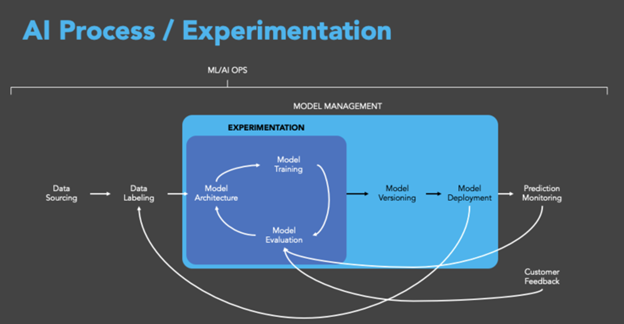
- Data Collection and Preparation
The first step in the AI training loop is the collection and preparation of data. This phase involves gathering raw data from various sources, which may include structured data from databases, unstructured data from text and images, and streaming data from real-time sources. The quality and relevance of the data collected are paramount, as they directly influence the effectiveness of the AI model.
Data preparation includes cleaning the data to remove inconsistencies and errors, normalizing data formats, and labeling data for supervised learning tasks. This process ensures that the data is of high quality and suitable for training AI models. Given that the success of AI largely depends on the quality of the data, this phase is often the most time-consuming and resource-intensive.
- Model Training
Once the data is prepared, the next step is model training. This involves selecting an appropriate algorithm and using the prepared data to train the model. In supervised learning, the model learns to map input data to the correct output based on the labeled examples provided. In unsupervised learning, the model identifies patterns and relationships within the data without the need for labeled outputs.
The training process involves feeding the data into the model in batches, adjusting the model parameters to minimize errors, and iterating through the dataset multiple times (epochs) until the model achieves the desired level of accuracy. This phase requires substantial computational resources and can benefit from specialized hardware such as GPUs and TPUs to accelerate the training process.
- Evaluation and Validation
After training, the model undergoes evaluation and validation to assess its performance. This step involves testing the model on a separate validation dataset that was not used during training. Key metrics such as accuracy, precision, recall, and F1-score are calculated to measure the model's performance and ensure it generalizes well to new, unseen data.
Validation also includes checking for overfitting, where the model performs well on training data but poorly on validation data, indicating it has learned noise rather than the underlying patterns. Techniques such as cross-validation, where the data is split into multiple folds and the model is trained and validated on each fold, help in providing a more robust assessment of model performance.
- Model Tuning and Optimization
Based on the evaluation results, the model may require tuning and optimization. This phase involves adjusting hyperparameters, such as learning rate, batch size, and the number of layers in a neural network, to improve the model's performance. Hyperparameter tuning can be performed manually or using automated techniques like grid or random searches.
Optimization also includes refining the model architecture, experimenting with different algorithms, and employing techniques like regularization to prevent overfitting. The goal is to achieve a balance between model complexity and performance, ensuring the model is both accurate and efficient.
- Deployment and Monitoring
Once the model is trained, validated, and optimized, it is deployed into a production environment where it can be used to make predictions on new data. Deployment involves integrating the model into existing systems and ensuring it operates seamlessly with other software components.
Continuous monitoring of the deployed model is essential to maintain its performance. Monitoring involves tracking key performance metrics, detecting drifts in data distribution, and updating the model as needed to adapt to changing data patterns. This phase ensures the AI system remains reliable and effective in real-world applications.
- Feedback Loop and Iteration
The AI training loop is an iterative process. Feedback from the deployment phase, including user interactions and performance metrics, is fed back into the system to inform subsequent rounds of data collection, model training, and tuning. This continuous improvement cycle allows the AI model to evolve and improve over time, adapting to new data and changing requirements.
4. Why Data Is as Important as Model Tuning
Data quality and quantity directly affect model performance, often surpassing the effects of algorithmic refinements. A robust data strategy achieves a critical balance between data and model optimization, essential for optimal AI outcomes and sustainable competitive advantage. This shift from a model-centric to a data-centric paradigm is crucial for organizations aiming to maximize the value of their AI initiatives.
The Pivotal Role of Data in AI
Andrew Ng from Stanford emphasizes that AI systems are composed of code and data, with data quality as crucial as the model itself. This realization requires a shift toward data-centric AI, focusing on improving data consistency and quality to enhance model performance. Data is the fuel that powers AI, and its quality directly affects the outcomes.
Data-Centric vs. Model-Centric AI
Historically, the majority of AI research and investment has focused on developing and improving models. This model-centric approach emphasizes algorithmic advancements and complex architectures, often overlooking the quality and consistency of the data fed into these models. While sophisticated models can achieve impressive results, they are highly dependent on the quality of the data they process.
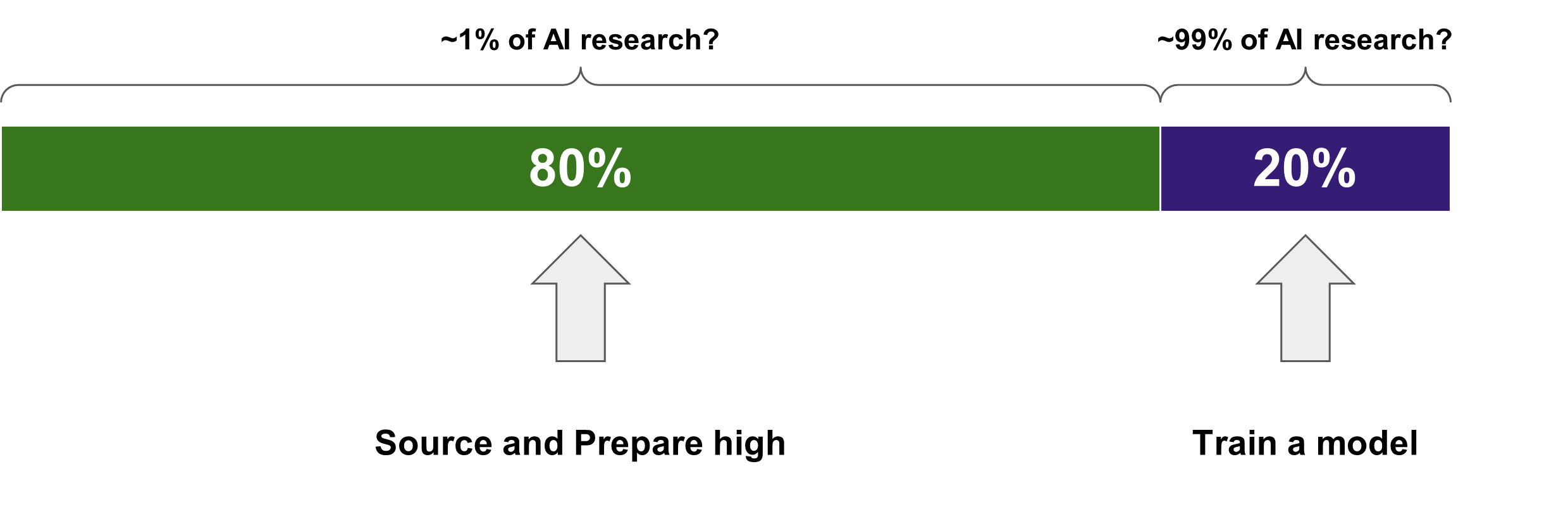
In contrast, the data-centric approach prioritizes the quality, consistency, and accuracy of data. This paradigm shift is driven by the understanding that high-quality data can significantly enhance model performance, even with simpler algorithms. Data-centric AI involves iterative improvements to the data, such as cleaning, labeling, and augmenting datasets, to enhance model performance. By focusing on data quality, organizations can achieve better results with simpler models, reducing complexity and increasing interpretability.
The Need for Accurately Labeled Data
The need for accurately labeled data is particularly critical in supervised learning. High-quality labeled data ensures that models learn the correct associations and can generalize well to new, unseen data. However, obtaining and maintaining such datasets can be challenging and resource-intensive, underscoring the importance of robust data management practices.
For enterprises, this means investing in data labeling tools, employing data augmentation techniques to increase the diversity and quantity of labeled data, and implementing rigorous data quality assurance processes. Additionally, leveraging automated data labeling and machine learning operations (MLOps) can streamline the data preparation process, reducing the burden on data scientists and ensuring that high-quality data is consistently available for model training.
See also: How External Data Is Revolutionizing Underwriting
The Enterprise Data Strategy
A data-centric approach is essential for enterprises aiming to leverage AI effectively. By prioritizing data quality and adopting robust data management practices, organizations can enhance the performance of AI models, regardless of whether they employ supervised or unsupervised learning techniques. This shift from model-centric to data-centric AI reflects a broader understanding that in the realm of AI, quality data is often more important than sophisticated algorithms.
If data quality is not given equal importance to model quality, organizations risk falling into a trap of perpetually compensating for model noise. When input data is noisy, inconsistent, or of poor quality, even the most advanced AI models will struggle to extract meaningful patterns. In such cases, data scientists often find themselves fine-tuning models or increasing model complexity to overcome the limitations of the data. This approach is not only inefficient but can lead to overfitting, where models perform well on training data but fail to generalize to new, unseen data. By focusing on improving data quality, enterprises can reduce noise at the source, allowing for simpler, more interpretable models that generalize better and require less computational resources. This data-first strategy ensures that AI efforts are built on a solid foundation, rather than constantly trying to overcome the limitations of poor-quality data.
Ensuring that enterprises have access to high-quality, accurately labeled data is a critical step toward realizing the full potential of AI technologies.
5. Potential Generative AI Approaches
Organizations can adopt different approaches to AI based on their strategic goals and technological capabilities. Each approach has distinct data implications that chief data officers (CDOs) must address to ensure successful AI implementations. The three primary approaches are: Taker, Shaper, and Maker.
Taker
The "Taker" approach involves consuming pre-existing AI services through basic interfaces such as application programming interfaces (APIs). This approach allows organizations to leverage AI capabilities without investing heavily in developing or fine-tuning models.
Data Implications:
- Data Quality: CDOs must ensure that the data fed into these pre-existing AI services is of high quality. Poor data quality can lead to inaccurate outputs, even if the underlying model is robust.
- Validation: It is crucial to validate the outputs of these AI services to ensure they meet business requirements. Continuous monitoring and validation processes should be established to maintain output reliability.
- Integration: Seamless integration of these AI services into existing workflows is essential. This involves aligning data formats and structures to be compatible with the API requirements.
Shaper
The "Shaper" approach involves accessing AI models and fine-tuning them with the organization’s own data. This approach offers more customization and can provide better alignment with specific business needs.
Data Implications:
- Data Management Evolution: CDOs need to assess how the business’s data management practices must evolve to support fine-tuning AI models. This includes improving data quality, consistency, and accessibility.
- Data Architecture: Changes to data architecture may be required to accommodate the specific needs of fine-tuning AI models. This involves ensuring that data storage, processing, and retrieval systems are optimized for AI workloads.
- Data Governance: Implementing strong data governance policies to manage data access, privacy, and security is essential when fine-tuning models with proprietary data.
Maker
The "Maker" approach involves building foundational AI models from scratch. This approach requires significant investment in data science capabilities and infrastructure but offers the highest level of customization and control.
Data Implications:
- Data Labeling and Tagging: Developing a sophisticated data labeling and tagging strategy is crucial. High-quality labeled data is the foundation of effective AI models. CDOs must invest in tools and processes for accurate data annotation.
- Data Infrastructure: Robust data infrastructure is needed to support large-scale data collection, storage, and processing. This includes scalable databases, high-performance computing resources, and advanced data pipelines.
- Continuous Improvement: Building foundational models requires continuous data collection and model iteration. Feedback loops should be established to incorporate new data and improve model accuracy over time.
The approach an organization takes toward AI—whether as a Taker, Shaper, or Maker—has significant implications for data management practices. CDOs play a critical role in ensuring that the data strategies align with the chosen AI approach, facilitating successful AI deployment and maximizing business value.
6. Core Components of an AI Data Strategy
An effective AI-driven data strategy encompasses several key components.
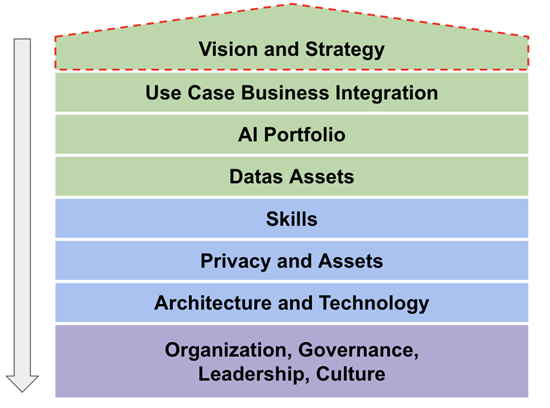
Vision and Strategy
Aligning data strategy with organizational goals is paramount. The absence of a coherent data strategy is a significant barrier to expanding AI capabilities. A robust data strategy provides a clear framework and timeline for successful AI deployment. This strategy should be revisited regularly to ensure alignment with evolving business goals and technological advancements.
Data Quality and Management
Data quality remains a persistent challenge for AI. Organizations must prioritize sourcing and preparing high-quality data. Employing methodologies like outlier detection, error correction, and data augmentation ensures the data used in AI models is accurate and reliable. Establishing data governance frameworks, including data stewardship and quality control processes, is essential for maintaining data integrity over time.
AI Integration and Governance
Integrating AI into business functions necessitates a comprehensive approach. This involves addressing technical aspects (architecture, data, skills) and strategic elements (business alignment, governance, leadership, and culture). Ensuring robust governance frameworks for data quality, privacy, and model transparency is essential. These frameworks should include clear policies for data access, usage, and protection, as well as mechanisms for monitoring and mitigating biases in AI models.
See also: Can AI Solve Underlying Data Problems?
7. Evolution of Data Architectures in the Context of AI
Future Trends and Considerations
The rise of generative AI introduces new requirements for data architectures. These include seamless data ingestion, diverse data storage solutions, tailored data processing techniques, and robust governance frameworks. As AI technologies evolve, the value of traditional degree credentials may shift toward a skills-based approach, fostering more equitable and efficient job training and placement.
Data Architectures
Modern data architectures must support the diverse and dynamic needs of AI applications. This includes integrating real-time data streams, enabling scalable data storage solutions, and supporting advanced data processing techniques such as parallel processing and distributed computing. Furthermore, robust data governance frameworks are essential to ensure data quality, privacy, and compliance with regulatory standards.
The Evolving Skill Set for the AI Era
As AI becomes more prevalent, the skills required in the workforce will evolve. While technical skills in AI and data science will remain crucial, there will be an increased demand for "human" skills. These include critical thinking, creativity, emotional intelligence, and the ability to work effectively with AI systems. Lifelong learning and adaptability will be essential in this ever-changing landscape.
Workforce Transformation
Organizations must invest in continuous learning and development programs to equip their workforce with the necessary skills. This includes offering training in AI and data science, as well as fostering a culture of innovation and adaptability. By nurturing a diverse skill set, organizations can better leverage AI technologies and drive sustainable growth.
8. Methodologies for Data-Centric AI
To effectively harness the potential of AI, organizations must adopt a data-centric approach, employing methodologies that enhance data quality and utility:
- Outlier Detection and Removal: Identifying and handling abnormal examples in datasets to maintain data integrity.
- Error Detection and Correction: Addressing incorrect values and labels to ensure accuracy.
- Establishing Consensus: Determining the truth from crowdsourced annotations to enhance data reliability.
- Data Augmentation: Adding examples to datasets to encode prior knowledge and improve model robustness.
- Feature Engineering and Selection: Manipulating data representations to optimize model performance.
- Active Learning: Selecting the most informative data to label next, thereby improving model training efficiency.
- Curriculum Learning: Ordering examples from easiest to hardest to facilitate better model training.
The evolution of data strategy is not just a trend; it's a necessity for organizations aiming to leverage AI for competitive advantage. By prioritizing data quality, aligning AI initiatives with business goals, and establishing strong governance frameworks, organizations can unlock the transformative potential of AI, driving productivity, innovation, and economic growth in the years to come.






